Liebe Leonie,
die Auswahl der Personen festzulegen, die du in deine Analyse einbeziehen willst, ist nicht ganz trivial. Würden wir davon ausgehen, dass jede Person nur eine einzige andauernde Episode in Biography aufweist, dann könntest du so vorgehen, wie du dir das gedacht hast, also:
in Biography nur die Episoden beibehalten, die andauern und dann alle Episoden droppen, deren sptype du nicht benötigst.
Da du jedoch zusätzlich nach unterschiedlichen spGap-Typen differenzieren möchtest, müsstest vorher die Informationen aus spGap an Biography mergen.
Hier eine kurze Stata-Syntax dazu:
use „SC6_spGap_D_10-0-1.dta“, clear
keep if subspell == 0
save " SC6_spGap_D_10-0-1_sub0.dta", replace
use " SC6_Biography_D_10-0-1.dta", clear
merge 1:1 ID_t splink using " SC6_spGap_D_10-0-1_sub0.dta"
drop if _merge == 2
keep if splast == 1
Ab hier könntest du dann nach Episodentyp und Gap-Typ auswählen, weil du nun auch die Informationen zum Gap-Typ in Variable ts29101 in Biography zur Verfügung hast.
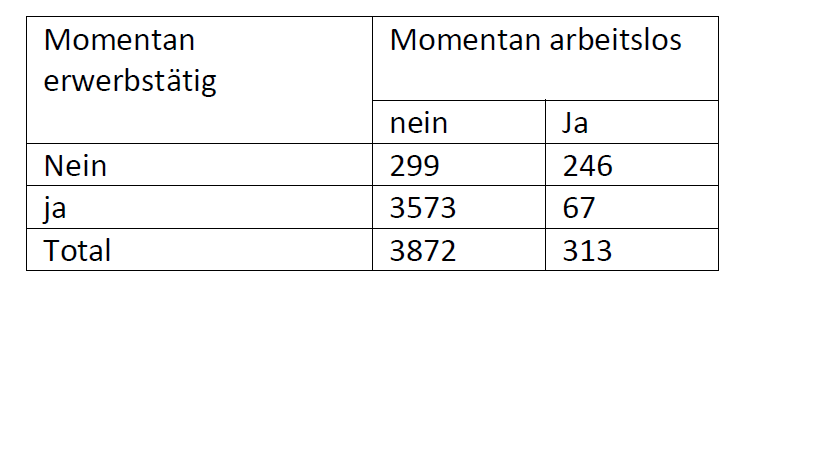
Leider gibt es jedoch nicht wenige Befragte, die zum letzten Interviewzeitpunkt mehrere Dinge gleichzeitig machen. Im aktuellen SC6-SUF gibt es innerhalb der insgesamt 17124 Befragten 3020 Befragte, die mehr als eine andauernde Episode angeben. In den Daten finden sich Extremfälle, die bis zu 6 andauernde Episoden angegeben haben. Bei Fällen, die mehr als eine andauernde Episode aufweisen, musst du auswählen, welche von diesen andauernden Episoden für dich die für deine Analysen relevante sein soll. So gibt es z.B. 150 Personen, die angeben sowohl eine andauernde Erwerbsepisode als auch eine andauernde Arbeitslosigkeitsepisode zu haben. Hier stellt sich die Frage, ob die Erwerbstätigkeit oder die Arbeitslosigkeit für dich wichtiger ist, oder ob die Erwerbstätigkeit erst dann relevanter als die Arbeitslosigkeit ist, wenn sie einen bestimmten zeitlichen Umfang übersteigt. Im letzteren Fall müsstest du zusätzliche Informationen zum zeitlichen Umfang der Erwerbstätigkeit aus spEmp in die Daten mit aufnehmen, die du für deine Selektionsentscheidung nutzt. Diese Information könnte jedoch wiederum verteilt sein über mehrere Erwerbsepisoden, da 1533 Fälle mehr als eine aktuelle Erwerbsepisode angeben.
Darüber hinaus gibt es beispielsweise 216 Personen, die eine aktuelle Erwerbstätigkeit und eine aktuelle Elterzeit haben.
Grundsätzlich löst man solche Probleme, bei denen mehrere Episoden infrage kommen und man sich für eine entscheiden muss, durch Priorisierung der Episoden nach Episodenarten oder/und Konstellationen von Episodeneigenschaften. Dazu bildet man einen Prioritätsindex, der umso höher ist, je relevanter bestimmte Episodeneigenschaften für die Selektion sind. Letztlich selektierst du dann, wenn eine befragte Person mehrere Episoden hat, diejenigen Episode als die für dich relevante, die von dir den höchsten Prioritätsindex bekommen hat.
Viele Grüße, Ralf.